25 Jun 2023
In this post, I would like to document briefly how I implemented my own Envoy control plane utilizing Envoy’s data plane API. The demo presented here is built for Docker swarm where dynamic resources for Envoy are updated by parsing labels of swarm services. Thus, the control plane should be run on a manager node. The demo code can be found in this GitHub repository. Another demo for Envoy running natively can be found here. The blog post, “Guidance for Building a Control Plane to Manage Envoy Proxy at the edge, as a gateway, or in a mesh,” by Christian Posta is highly recommended before jumping into the topic of Envoy dynamic configuration.
22 Jun 2023
It is quite fun watching people exchanging thoughts and ideas on Twitter, even though from time to time people no longer care about their intellectual humility and turn the discussion into a fight. Everyone, more or less, wants to be heard. The Internet has taught me that information sharing, as a human instinct, eventually makes social progress possible. This is especially true for OSS (“open source software”) in that to facilitate open discussions and to have faith in collective intelligence are what we have luckily done right so far.
28 May 2023
新一轮财税体制改革,从逻辑看,预算管理制度改革是基础、要先行;收入划分改革需在相关税种税制改革基本完成后进行;而建立事权与支出责任相适应的制度需要量化指标并形成有共识的方案。
【读书摘记】楼继伟著《中国政府间财政关系再思考》,中国财政经济出版社2013年版。另附楼继伟早期论文阅读笔记以供学习交流。
10 May 2023
In this post, I would like to present some basic observations on performance differences between two data serialization protocols: Protocol Buffer (Protobuf) and JSON. Specifically, I would like to compare them based on serialization/de-serialization speeds and the memory footprint of data encoding for different data sizes.
24 Apr 2023
In this post, I would like to revise and update results for the shared-cache DoS attack that I presented here.
22 Apr 2023
In this post, I would like to present performance measurements for Apache and NGINX web servers on the same free-tier AWS EC2 instance created here. Experiments were conducted inside the AWS EC2 instance (rather than connected from my local machine through SSH) using the Apache Bench (ab) command-line tool. For each run, I explicitly specified the number of HTTP GET requests made to the website I wrote for CSE 503S Module 5 and the level of concurrency (i.e., the number of multiple requests to perform at a time).
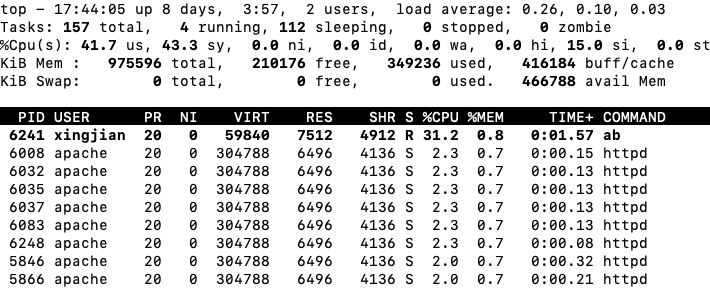
Figure 1: Output of the top command
15 Apr 2023
I document in this post my attempt to reproduce eight experiments described in Cloudflare’s 03/20/2023 blog post on an AWS EC2 instance. Python programs are provided here.
A TCP/IP connection is identified by a 4-tuple: {source IP, source port, destination IP, destination port}. To establish a TCP/IP connection, only a destination IP and port number are needed. The operating system automatically selects source IP and port. On Linux we can see which source IP will be chosen with ip route get.
11 Apr 2023
The Linux connection tracking subsystem (in many scenarios called “the conntrack table”), built on top of the Netfilter framework, stores information about the state of a network connection in a memory structure that contains the source and destination IP addresses, port number pairs, protocol types, state, and timeout.
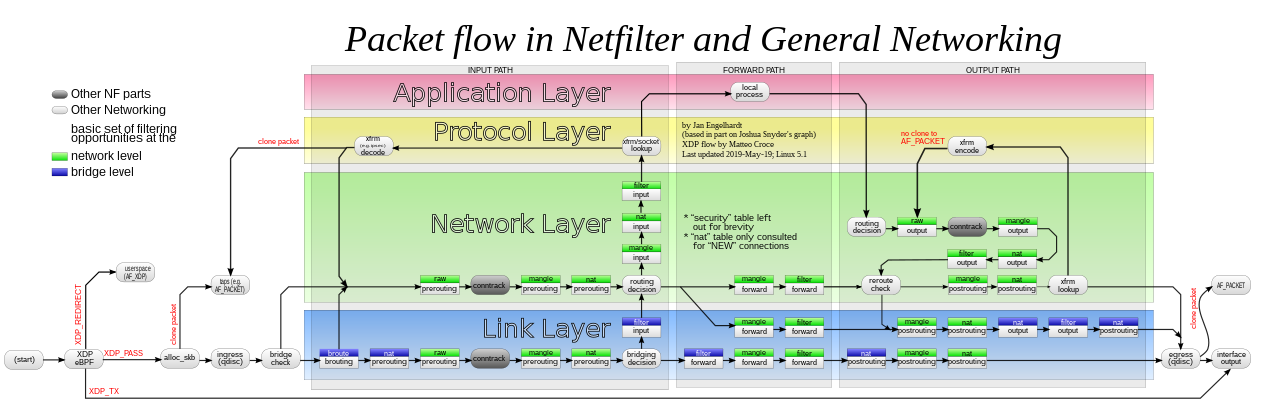
Schematic for the packet flow paths through Linux networking and Xtables (Author: Jan Engelhardt)
This post by Arthur Chiao (simplified Chinese: 赵亚楠) provides a solid knowledge base for understanding connection tracking in Linux. I document here my attempt to reproduce two tests described in Cloudflare’s 04/06/2020 blog post on an AWS EC2 instance.
07 Apr 2023
The drama of Central Europe is doubled by that of the West, which does not care to see it, has never even noticed its disappearance; which does not register its significance, because the West no longer understands itself, either, in its own cultural role. In the Middle Ages, Europe's unity rested on Christianity; then in modern times, on the Enlightenment. But these days that coherence is replaced by a culture of entertainment, bound up with markets and information technologies. So what meaning can we assign to the European project?
This seminal essay by Milan Kundera, translated from the French by Edmund White, was published as “The Tragedy of Central Europe,” in the New York Review of Books (April 26, 1984).
The original footnotes by Milan Kundera are those starting with “MK” in the Footnotes section.
28 Mar 2023
Recently, I have been learning the basics of Envoy, which is a high-performance, open source, application-level service proxy written in C++. Envoy was developed at Lyft, where large distributed systems problem needed to be overcome. Envoy was not originally intended as an edge proxy, but was designed to be deployed as a sidecar. The union of performance, extensibility, and dynamic configurability has made Envoy the universal data plane in cloud native architectures for application/L7 networking solutions.
26 Mar 2023
When implementing the multi-room chat server project for Washington University CSE 503S (Spring 2023), I encountered the issue of loading external static files (e.g., CSS stylesheets, JavaScript programs, and images, etc.) into the web page. This post documents a simple solution inspired by this MDN article.
14 Mar 2023
Network namespaces entered the Linux kernel in version 2.6.24. They partition the use of the system resources associated with networking—network devices, addresses, ports, routes, firewall rules, etc.—into separate boxes, essentially virtualizing the network within a single running kernel instance.
08 Mar 2023
For general overview and the setup packages for these two labs, please go to SEED Labs official website. The lab assignments were conducted using Docker Compose on an AWS EC2 instance running the SEED Ubuntu 20.04 VM. For each lab, download the Labsetup.zip file, unzip it, enter the Labsetup folder, and use the docker-compose.yml file to set up the lab environment.
Let’s first take a quick run-through of the Transmission Control Protocol (TCP).
02 Mar 2023
Well stated by Julia Evans:
The word “container” doesn’t mean anything super precise. Basically there are a few new Linux kernel features (“namespaces” and “cgroups”) that let you isolate processes from each other. When you use those features, you call it “container”.
Docker is a fully-featured container environment that automates the creation of containers, and allows the monitoring and management of multiple containers, even across multiple hosts. The Linux container technologies have a much longer history than Docker, but Docker makes everything easier.
28 Feb 2023
There are two famously hard problems in public key cryptography: one is integer factorization (for RSA algorithm) and the other is discrete logarithm computation in a finite group (for Diffie-Hellman key exchange).
Diffie-Hellman algorithm is widely used in secure network communications. According to RFC2631:
Diffie-Hellman key agreement requires that both the sender and recipient of a message have key pairs. By combining one’s private key and the other party’s public key, both parties can compute the same shared secret number. This number can then be converted into cryptographic keying material. That keying material is typically used as a key-encryption key (KEK) to encrypt (wrap) a content-encryption key (CEK) which is in turn used to encrypt the message data.
12 Feb 2023
Some writeup for Washington University CSE 522S: Studio 9 “CPU Control and Timing Events”.
The parallel_dense_mm.c program shown below, using the OpenMP library to run in parallel,
- takes a single command-line argument,
- creates two dense matrices of size specified by the command-line argument,
- fills them with randomly-generated values, and then
- multiplies them.
06 Feb 2023
Some writeup for Washington University CSE 522S: Studio 8 “Observing Memory Events”, Exercise 4 through 6.
Here I rediscovered some history episode about fork bomb attack. In this post, I would like to test a fork bomb program which additionally makes malloc() function calls that generate significant memory usage for Linux control groups:
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#define PAGE_SIZE 4096
int main()
{
unsigned int counter = 0;
while (1) {
printf("%d. Allocating an entire page...\n", ++counter);
void *p = malloc(PAGE_SIZE);
memset(p, 0, PAGE_SIZE);
sleep(1);
printf("%d. Forking a child...\n", counter);
fork();
sleep(1);
}
return 0;
}
05 Feb 2023
所以过去这些年我们一直在建议说我们是不是可以接受一种理论,就是说把文化和文明做一点区分,文化是与生俱来的习惯,是使不同的民族保持不同面貌的东西,是不怎么会变化的东西。而文明是一种需要学习得来的,社会群体交往的规则,是使不同的人群差异越来越少的东西,是不断进步的、是大家遵循的一种交往的理性。假定我们能在意识中区分文化和文明,我们就知道文化没有好坏之别,文明才有进步和落后的区别。如果在这样的意义上来理解,那么我们就可以既拥抱文明,又守护文化。
【读书摘记】
- 第一部分 —— 葛兆光著《中国思想史·导论:思想史的写法》复旦大学出版社2009年版。
- 第二部分 —— 葛兆光著《宅兹中国:重建有关“中国”的历史论述》,中华书局2011年简体中文版。英文版由Jesse Field和秦方翻译,荷兰Koninklijke Brill出版社2017年出版。
- 第三部分 —— 葛兆光著《何为中国:疆域、民族、文化与历史》,牛津大学出版社2014年繁体中文版。英文版由Michael Gibbs Hill翻译,The Belknap Press of Harvard University Press 2018年出版。
关于“宅兹中国”这一书名,1963年出土于中国陕西省宝鸡市金台区贾村的何尊内底铸有铭文:
余其宅兹中国,自兹乂民。
这是目前发现的最早的“中国”一词的用例。
30 Jan 2023
China was neither primitive nor was its economy simple; rather it was vital, changing, developing. But it did not modernize. It did not accept the challenge of the industrial West and "develop" in this special sense of the term.
【读书摘记】
- Frank H. H. King, Money and Monetary Policy in China: 1845-1895, Harvard University Press, 1965。
这部专著记录了十九世纪下半叶 —— 1842年第一次鸦片战争结束至1895年中日《马关条约》签订 —— 清代中国的货币系统如何适应来自外部工业文明的挑战。作者景复朗,中国经济史学家,香港大学亚洲研究中心创始主任(1968-1979),除本书以外,其著作还包括四卷本汇丰银行史。
25 Jan 2023
Some writeup for
- Washington University CSE 422S: “Operating Systems Organization”, Studio 13: “VFS Layer”, and
- Washington University CSE 522S: “Advanced Operating Systems”, Studio 4: “Observing File System Events”, Exercises 2 through 4.
Please go visit home pages of Dr. Christopher D. Gill and Dr. James Orr for more information about these courses.
21 Jan 2023
This post documents solutions to picoCTF web exploitation challenges. To access picoGym Practice Challenges on the picoCTF website, a registered account is needed. Some of the challenges can be more elegantly solved with automation scripts written in Python.
20 Jan 2023
Exercise 3, 4, and 5 from Washington University CSE 522S: “Advanced Operating Systems” Studio 3: “Hardware Counters and Loadable Kernel Modules”. For Linux kernel version used in the course and Raspberry Pi configuration, please refer to this post. A month ago, I tried to get timing measurements from userspace on my Raspberry Pi, but failed. This post provides some sort of solution. Programs shown here are largely adapted from the starter code provided by Dr. Marion Sudvarg.
19 Jan 2023
Individual portion of Module 2 from CSE 330/503S: “Rapid Prototype Development and Creative Programming” at Washington University in St. Louis. The Apache web server will be installed and configured on an AWS EC2 instance. A Mac laptop is used as the local machine.
18 Jan 2023
This post contains a list of computer security resources from Dr. Stephen V. Cole at Washington University in St. Louis. Other resources can also be found at WUSTL B34R5HELL team’s GitHub repo.
16 Jan 2023
Studio 1 and 2 of CSE 522S: “Advanced Operating Systems” at Washington University in St. Louis. I am using a Raspberry Pi 3 Model B Plus for the course, which has a quad-core Arm® Cortex-A53 (ARMv8) CPU.
01 Jan 2023
A concurrent stack is a data structure linearizable to a sequential stack that provides push and pop operations with the usual LIFO semantics. Linearizability is the de facto standard correctness condition for concurrent algorithms. Intuitively, an algorithm is linearizable with respect to a sequential specification if each execution of the algorithm is equivalent to some sequential execution of the specification, where the order between the non-overlapping methods is preserved. In this post, I would like to review a Java implementation of a concurrent stack data structure called the elimination back-off stack. Those who are interested in C++ implementations of concurrent data structures may find this repo useful. I also found this article by Mark Moir and Nir Shavit a good source for concurrent programming.
31 Dec 2022
中国这么大,底层生活这么丰富,南北方都有创造。下去调查,把调查的东西拿来,互相比较、鉴别,从中发现合理因素,然后先用短期政策承认,再把这个政策长期化,如果发现效果好,上升为法律、国家制度。这就是我体会到的改革。
【读书摘记】
- 周其仁著《货币的教训 —— 汇率与货币系列评论》,北京大学出版社2012年版。重要学术概念和相关历史背景由补注给出。
周其仁曾在《改革的逻辑》自序中这样解释中国的改革:
其实世界上的各种经济体制互相比赛一件事情,那就是纠错能力。 · · · · · · 改革无非是系统性地纠错。这里存在一个悖论:计划体制本来就是因为纠错能力不够强,非积累起很多问题才需要改革。但打出改革的旗帜,我们体制的纠错能力就能自动变强吗? · · · · · · 既然改革这么难,那么干脆不改了行不行?干脆宣布中国已经建成了新体制,再也无需改革,行不行?想来想去,答案是“不行”。因为改了一半不再改,大的麻烦在后面。大体有三个层面。第一个层面,不继续在一些关键领域推进改革,不继续推进社会主义市场经济方向的改革,不推进健全社会主义民主和法制的政治改革,很多社会矛盾会呈现连锁爆发趋势。 · · · · · · 第二个层面,更年轻的人群成为社会的主体,他们对体制、政策以及自己所处环境的评价,有不同于上一代人的新参照系。 · · · · · · 第三个层面,现在很多制度性的变量改得过慢,老不到位,正在激发越来越多的法外行为、法外现象。
市场化改革让中国的货币深化(广义货币比上GDP)势不可挡。
14 Dec 2022
This post is some notes taken from Andrew W. Appel’s 1992 book, Compiling with Continuations.
05 Dec 2022
Homework 6 of the programming language course taught by Professor Dan Grossman from University of Washington. Please refer to this link for instructions and provided code.
03 Dec 2022
I have attempted to shed light on whys and hows regarding the Spectre and Meltdown attacks with materials drawn from SEED Labs 2.0. A MacBook Air equipped with Intel Core i5-5250U was used to run the C programs. Here in this post, I would like to address the problem of launching microarchitectural attacks on a Raspberry Pi 3 Model B+, which is an ARM machine.
11 Nov 2022
For general overview and the setup package for this lab, please go to SEED Labs official website. The lab assignment was conducted using SEED virtual machine configured on a AWS EC2 instance. On the SEED Ubuntu 20.04 VM, Tasks 1 to 6 still work as expected, but Tasks 7 and 8 will not work due to the countermeasures implemented inside the OS.
Please refer to this post for detailed explanations of Tasks 1 and 2.
02 Nov 2022
Homework 5 of the programming language course taught by Professor Dan Grossman from University of Washington.
Racket programming language is the grandchild of LISP. Compared to ML, Racket does not use a static type system and has a very minimalist and uniform syntax. Racket’s struct, which will be used extensively in this assignment, is like an ML constructor. A struct definition may look like:
(struct foo (bar baz quux) #:transparent)
26 Oct 2022
Some code collected from the Homework 4 of “Programming Languages, Part B” taught by Professor Dan Grossman from University of Washington and the Warm-Up exercise of CSE 425S: “Programming Systems and Languages” taught by Professor Dennis Cosgrove from Washington University in St. Louis (also see Professor Chris Gill’s Home Page for past offerings).
Professor Dennis Cosgrove hosts a YouTube channel which might be of interest to those computer science newcomers.
20 Oct 2022
For general overview and the setup package for this lab, please go to SEED Labs official website. The lab assignment was conducted using Docker Compose, which does not depend much on the SEED VM.
On September 24, 2014, a severe vulnerability was found in the bash program, which is used by many web servers to process CGI requests. The vulnerability allows attackers to run arbitrary commands on the affected servers. The attack is quite easy to launch, and millions of attacks and probes were recorded following the discovery of the vulnerability. It is called Shellshock. This Cloudflare’s blog post is a good read.
13 Oct 2022
In “Defeating ASLR: The Return-to-pop Method”, I constructed a payload that used the ret and pop-ret instructions to inject shellcode into our vulnerable program with ASLR enabled but non-executable stack (hereinafter “NX”) disabled. The payload worked just as expected because we knew that the memory space between ans_buf and the address we were returning to is larger than our shellcode. What if the memory space is not large enough? More importantly, what if we do not have a shellcode at our disposal? In this post, I would like to describe an exploitation technique called “return-to-libc”, which makes use of existing code (“libc” is used by convention as a shorthand for the “standard C library”) to spawn a shell. The documentation is organized into two parts: for the first part, the ASLR protection is turned off; and for the second part, both ASLR and NX are enabled.
06 Oct 2022
In this post, I would like to describe a Standard ML implementation of binary search tree (BST), in which every tree node n satisfies the condition that n’s left child, if exists, has a value less than that of n and n’s right child, if exists, has a value greater than that of n. Each non-empty tree node records information about its own element or value along with its descendant(s). A client should be able to
find the element of a node by key;insert elements onto an existing tree;remove nodes from an existing tree;- perform tree traversal using higher order functions.
The BST is kept as general as possible such that the elements and keys can be any types.
30 Sep 2022
In this post, I would like to launch an attack on a 32-bit Ubuntu 20.04 system against a simple userspace program with buffer overflow vulnerability. The procedure presented here implements a stack juggling method called “return-to-pop”. The exploitation aims to bypass Address Space Layout Randomization (ASLR) (/proc/sys/kernel/randomize_va_space defaults to “2”, which means full randomization), and gains the shell access.
26 Sep 2022
Homework 3 of the programming language course taught by Professor Dan Grossman from University of Washington.
Standard ML extensively revised earlier dialects of the functional programming language ML, including the module facility that supports large-scale program development. The use of pattern matching to access components of aggregate data structures is one of the most powerful, and distinctive, features of ML family.
18 Sep 2022
It was a cozy Midwest Sunday morning. I woke up a little later than usual and just couldn’t decide whether I should go to the lab. Typically, to deal with this situation, I will first check the weather using iOS’s built-in weather app. However, a random thought came to me: why not just let the Terminal display weather information for me?
08 Aug 2022
There are two kinds of forecasters: those who don't know, and those who don't know they don't know.
Summers’ recent research papers may be quite informative if we look forward to some technical judgments towards the U.S. macro-economic conditions as well as the Fed’s goals during an abnormal time.
17 Jul 2022
This post guides through some background knowledge required in the SEED Meltdown and Spectre Attack Labs.
The security of userspace applications and the operating system kernel is essentially dependent upon memory protection. Security patches have been applied to prevent address information leakage. But address information can still be exploited on the microarchitectural level even if the operating system does its job.
In 2017, it was discovered that many modern processors are vulnerable to attacks called Meltdown (CVE-2017-5754) and Spectre (CVE-2017-5753 and CVE-2017-5715). Meltdown allows a user-level program to read data stored inside the kernel memory, which causes a trap. But before the trap is issued, the instructions that follow the access leak the contents of the accessed memory through a cache covert channel. Meltdown vulnerability affects Intel x86 microprocessors and some ARM-based microprocessors. Spectre exploits a race condition vulnerability in the design of the speculative execution implemented in most CPUs, which allows a malicious program to read the data from the area that is not accessible to it. Unlike the Meltdown attack, the restricted area does not need to be inside the kernel; it can be in the same process space as the malicious program, making defending the Spectre attack much more difficult.
01 May 2022
Success breeds a disregard of the possibility of failure.
The term “Copula” (from the Latin for “link”) was coined by Abe Sklar in his 1959 article, which was written in French. Copulas have been widely used, though not always applied properly, in financial and econometric modeling, especially in pricing securities that depend on many underlying securities. Formally put, for an $n$-variate function $F$, the copula associated with $F$ is a distribution function \(C: [0, 1]^{n} \rightarrow [0, 1]\) that satisfies:
\[F(y_{1}, \dots , y_{n}) = C(F_{1}(y_{1}), \dots , F_{n}(y_{n}) ; \theta),\]
where \(\theta\) is a parameter of the copula called the dependence parameter, which means dependence between the marginals. This is a frequent starting point of empirical applications.
21 Apr 2022
The previous post gives a broad-brush survey of radix tree data structure in Linux. Another useful tree-based API is red-black tree, which has been particularly crucial for Linux kernel memory management.
A red-black tree is a binary search tree which has the following red-black properties:
- Every node is either red or black.
- Every leaf (
NULL) is black.
- If a node is red, then both of its children are black.
- Every simple path from a node to a descendant leaf contains the same number of black nodes.
20 Apr 2022
On SOSP 2015 History Day, Peter J. Denning in his presentation slides listed six patterns he learned from operating systems research — there is never certainty; occasionally an insight charts a new direction; technology inflection points may trigger avalanches; searching for what works: building, experimenting, tinkering; always in a social network; theory follows practice.
This post digs into Linux’s implementation of the radix tree API. This GitBook is absolutely great but covers little about the radix tree. So I decided to set out on my own journey. The most complex and important user of Linux’s radix tree API is the page cache: every time we look up a page in a file, we consult the corresponding radix tree to see if the page is already in the cache. Besides, both the proc pseudo-filesystem and SCTP rely upon a minimalistic version of radix tree called generic radix tree (or genradix for short) that allocates one page of entries at a time. genradix is not discussed in this post.
05 Mar 2022
Washington University E81 CSE 422S: “Operating Systems Organization” Studio 11: “Kernel Memory Management”, Spring 2022. I’m using a Raspberry Pi 3 Model B+ running Linux kernel version 5.4.42. The output produced by running uname -a is:
Linux xingjian 5.4.42-v7xingjian #1 SMP PREEMPT Thu Feb 10 14:37:24 CST 2022 armv7l GNU/Linux
The Linux kernel offers several approaches to memory management, including a variety of memory allocation and deallocation facilities for use in kernel space, which offer different trade-offs between memory utilization and performance, as well as different guarantees on physical contiguity. In this studio, we will:
- Allocate and deallocate memory for different numbers of objects, using the kernel-level page allocator.
- Use address translation structures to manipulate the memory allocated via the kernel-level page allocator.
09 Jan 2022
For general overview and the setup package for this lab, please go to SEED Labs official website. The lab assignment was conducted using SEED virtual machine configured on a AWS EC2 instance.
25 Dec 2021
In this post, I would like to give a brief account of two Linux system calls —— fork(2) and execve(2) —— with operating system kernel implementation details (not glibc wrappers) presented and two code examples explained. fork(2) and execve(2) are commonly used by Linux processes from both user and kernel spaces. In particular, as you can see below, they are involved in the Linux kernel initialization process (the GitBook “Linux Insides” provides a comprehensive discussion on this topic).
Note that the number enclosed in parentheses after the object name indicates the section of the Linux man pages in which the object is described. The Linux man pages is divided into eight sections:
1. User commands and tools;
2. Linux system calls and system call wrappers;
3. Library functions excluding system call wrappers;
4. Special files (devices);
5. File formats and filesystems;
6. Games and funny little programs available on the system;
7. Overview and miscellany section;
8. Administration and privileged commands.
29 Nov 2021
For general overview and the setup package for this lab, please go to SEED Labs official website. The lab assignment was conducted using SEED virtual machine configured on a AWS EC2 instance.
A race condition occurs when multiple processes access and manipulate the same data concurrently, and the outcome of the execution depends on the particular order in which the access takes place. If a privileged program has a race condition vulnerability, attackers can run a parallel process to “race” against the privileged program, with an intention to change the behaviors of the program. This lab covers the following topics:
- Race condition vulnerability
- Sticky symlink protection
- Principle of least privilege
17 Nov 2021
For general overview and the setup package for this lab, please go to SEED Labs official website. The lab assignment was conducted using SEED virtual machine configured on a AWS EC2 instance.
01 Oct 2021
A reproducible record of how to install Rust and CMake on macOS. Rust is a memory-safe system programming language that has gained popularity over recent years. CMake is a cross-platform, compiler-independent, and open-source build system generator.
24 Sep 2021
作为中国“冷战国际史”这一新兴学科的创建者之一,沈志华教授为该学科的建立和发展做出了巨大的贡献。他自费从俄国和美国收集了大量宝贵的第一手档案文献,并无偿地提供给国内外学者使用,从而为该学科的长足发展奠定了坚实基础。而他本人,更是与这些档案朝夕相处,潜心研究,近二十年来主编了多部档案文献集,发表了大量的学术论文和专著。这些成果,在很大程度上改写了中国乃至国际史学界对中苏关系、朝鲜战争等重大历史过程和历史事件的叙述。
【读书摘记】
- 沈志华:《冷战在亚洲:朝鲜战争与中国出兵朝鲜》,北京:九州出版社,2013年。
05 Sep 2021
深林有歧途,
败叶掩足印,
举步入荒径,
只为少人行。
【读书摘记】
- 第一部分 —— 许倬云著《万古江河:中国历史文化的转折与开展》,湖南人民出版社2017年简体中文版。本书英文版 —— China: A New Cultural History —— 由Timothy D. Baker, Jr.和Michael S. Duke翻译,美国哥伦比亚大学出版社于2012年6月出版。
- 第二部分 —— 许倬云著《说中国:一个不断变化的复杂共同体》,广西师范大学出版社2015年简体中文版。
31 Jul 2021
凤泊鸾飘廿九霜,
如何未老便还乡。
此行看遍边关月,
不见江南总断肠。
【读书摘记】
- 余英时著《论天人之际:中国古代思想起源试探》,中华书局2014年简体中文版。
葛兆光曾在《几回林下话沧桑——我们所认识的余英时先生》一文中着重提到本书,以下为部分抄录:
二〇一三年的冬天,记得是十二月九日,正是普镇下第一场雪的后一天,也是普镇下第二场雪的前一天,那天下午,路上积雪稍稍化开,我正好有事外出,突然余先生和陈先生驾车来到Lawrence Drive我的住处,把厚厚一叠文稿交给内人戴燕,说这是二〇一四年一月台北联经出版公司即将出版的新书《论天人之际:中国古代思想起源试探》的最后一校,上面还有他自己若干亲笔校改的痕迹,余先生嘱咐我们看一看。
傍晚,我从外面回来开始拜读,越读越觉得兴味盎然,略有感想便匆匆记下,有时也拿起电话来和余先生乱聊,记得我一口气看了两个晚上加一个白天,不知不觉,普镇又已是漫天飞雪,遥望窗外,已经是白茫茫的一片。
这是我给余先生《论天人之际》一书写书评《向内在超越之路》的缘起。我觉得,余先生这部书的问世,使余先生对于中国知识人的历史和思想文化的历史,完成了最后的一块拼图,形成了他“从尧到毛”、贯通上下的一个清晰、独特和完整的历史叙述。
如果说,在前此的余先生各种著作中,我们可以看到这种注重“内在超越”的思想文化,如何在汉代成为主流并顺流而下,在《中国知识阶层史论(古代篇)》中看到了汉晋以来“士”的新自觉和新思潮,以及名教危机与魏晋士风演变,在《朱熹的历史世界》及《宋明理学与政治文化》中又看到唐宋以后士大夫的“得君行道”,以及理想主义受挫之后逐渐发展出“觉民行道”,在《戴震与章学诚》等清代学术史论著中看到知识阶层中的两种取向,最终在二十世纪看到了中国知识人的“边缘化”,在《重寻胡适历程》和《未尽的才情》中更看到了二十世纪知识人如胡适和顾颉刚的思想、学术、生活和命运。
那么,在《论天人之际》中余先生上溯源头,在古文献与考古发掘中寻找古代礼乐传统、祭祀仪式中的“巫”,指出他们如何逐渐“蜕变”,把“天命”、“鬼神”这些外在于人心的神秘力量,转换为超越的精神力量和道德责任,在“轴心时代”奠定了古代思想文化的基调。这是贯穿古今的一个中国思想史,也是绵绵不绝的一个中国文化史。
{kind=link}