Linux Filesystem Forensics
25 Jan 2023
Some writeup for
- Washington University CSE 422S: “Operating Systems Organization”, Studio 13: “VFS Layer”, and
- Washington University CSE 522S: “Advanced Operating Systems”, Studio 4: “Observing File System Events”, Exercises 2 through 4.
Please go visit home pages of Dr. Christopher D. Gill and Dr. James Orr for more information about these courses.
Applying scientific analysis to system behavior (often called system forensics, even if such “detective work” is being used for purposes beyond the scope of legal investigation suggested by the term’s dictionary definition) begins with detailed observation. For example,
- It may not be enough to know that a file no longer is found in a certain directory; was it moved to another directory, or was it deleted from the file system?
- What was the file’s “history”?
- Were its contents ever updated since it was created?
- Were its metadata ever changed?
Further, such observation requires a careful understanding of the nature of the file and the filesystem on which it resides.
- What does a directory’s path tell us about the physical filesystem (if any) on which the directory resides?
- Can a filesystem be entirely virtual — that is, backed only by structures in memory, and not on disk?
- What does it mean that a file “is found” within a directory?
- Does the existence of the file depend on the existence of the directory, or does the directory merely contain a pointer to the file? What are the implications?
- Can a file exist in two directories at once (or none at all)?
Table of Contents
Linux df, ls, and mount Utilities
Unix is heavily based on the filesystem concept; almost everything in Unix can be treated as a file. The kernel builds a structured filesystem on top of unstructured hardware, and the resulting file abstraction is heavily used throughout the whole system. In addition, Linux supports multiple filesystem types, that is, different ways of organizing data on the physical medium1.
The GNU version of df displays the amount of space available on the filesystem containing each file name argument. It is also useful for showing which filesystems are mounted2, and where the corresponding mount points reside in the virtual filesystem hierarchy. For example, If I issue the command df -h under /project/scratch01/compile/x.xingjian, where the -h option tells df to print sizes in powers of \(1024\):
Filesystem Size Used Avail Use% Mounted on
tmpfs 63G 0 63G 0% /sys/fs/cgroup
nfs.seas.wustl.edu:/seaslab/home-lab 18T 11T 6.9T 61% /home/warehouse
compute-scratch02.engr.wustl.edu:/export/scratch01 1.0T 665G 360G 65% /project/scratch01
A mount in the Linux kernel is represented by a data structure called vfsmount:
// In: include/linux/mount.h
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
struct user_namespace *mnt_userns;
} __randomize_layout;
All mounts form a tree-like structure, with a child mount structure holding a reference to the parent mount structure. Whenever a mount operation is invoked, (1) a vfsmount structure is created which holds a reference to a new superblock structure created from the filesystem to be mounted on the disk, and (2) the dentry of the mount point as well as the dentry of the mounted tree is populated. The dentry has a reference to the vfsmount. This is where the Linux’s virtual filesystem (VFS) distinguishes between a directory and a mount point. During a pathname lookup, the vfsmount is found in a dentry, the inode number 2 on the mounted device is used (inode 2 is reserved for root directory and indicates starting of filesystem inodes). Next section provides a more detailed discussion about VFS.
Now, on the Raspberry Pi, let’s create a directory tree that looks something like this:
.
|--studio4
|--subdir0
|--myfile
|--subdir1
|--subdir2
Navigate into subdir1 and create a hard link to the file in subdir0:
cd /path/to/studio4/subdir1
# Create a link to /path/to/studio4/subdir0/myfile
# in the current directory
ln ../subdir0/myfile
(I gave a brief recap on hard links in Linux here.)
We can write a userspace C program that emulates some of the behavior of the ln utility making use of the link() system call:
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <stdio.h>
#define WD "myfile" /* working directory */
void print_usage(char *program_name)
{
printf("Usage: %s <first-arg> <second-arg>(optional)\n", program_name);
}
void create_link(char *oldpath, char *newpath)
{
int r;
r = link((const char *)oldpath, (const char *)newpath);
if (r == -1) {
fprintf(stderr, "Error creating link: %s\n", strerror(errno));
}
}
int main(int argc, char *argv[])
{
if (argc == 2) {
/* create a link in working directory */
create_link(argv[1], WD);
} else if (argc == 3) {
create_link(argv[1], argv[2]);
} else {
print_usage(argv[0]);
}
return 0;
}
Compile and run the program:
pi@xingjian:~/Documents/userspace/cse522s $ gcc link.c -o link
pi@xingjian:~/Documents/userspace/cse522s $ ./link
Usage: ./link <first-arg> <second-arg>(optional)
pi@xingjian:~/Documents/userspace/cse522s $ ./link studio4/subdir0/myfile
pi@xingjian:~/Documents/userspace/cse522s $ ls
link myfile
link.c studio4
pi@xingjian:~/Documents/userspace/cse522s $ rm -rf myfile
pi@xingjian:~/Documents/userspace/cse522s $ ./link studio4/subdir0/myfile studio4/subdir2/myfile
pi@xingjian:~/Documents/userspace/cse522s $ ls -i studio4
390045 subdir0 390046 subdir1 390047 subdir2
pi@xingjian:~/Documents/userspace/cse522s $ ls -la studio4/subdir2
total 8
drwxr-xr-x 2 pi pi 4096 Jan 25 17:08 .
drwxr-xr-x 5 pi pi 4096 Jan 25 16:44 ..
-rw-r--r-- 3 pi pi 0 Jan 25 16:44 myfile
pi@xingjian:~/Documents/userspace/cse522s $ cd studio4
pi@xingjian:~/Documents/userspace/cse522s/studio4 $ ls -i *
subdir0:
390048 myfile
subdir1:
390048 myfile
subdir2:
390048 myfile
According to this RHEL online document:
When you mount a filesystem using the
mountcommand without all required information, that is without the device name, the target directory or the filesystem type, themountutility reads the content of the/etc/fstabfile to check if the given filesystem is listed there. The/etc/fstabfile contains a list of device names and the directories in which the selected filesystems are set to be mounted as well as the filesystem type and mount options.
Since Linux 2.4.0, it is possible to remount part of the file hierarchy somewhere else with the command:
mount --bind olddir newdir
Inside studio4, create another two subdirectories each of which contains a newly touched myfile:
.
|--studio4
|--subdir0
|--myfile (original myfile)
|--subdir1
|--myfile (link to subdir0/myfile)
|--subdir2
|--myfile (link to subdir0/myfile)
|--subdir3
|--myfile (just created)
|--subdir4
|--myfile (just created)
The process of bind mounting results in creating vfsmount structure that points to the dentry of the directory3. Let’s try out some bind mount commands:
pi@xingjian:~/Documents/userspace/cse522s/studio4 $ cd subdir3
pi@xingjian:~/Documents/userspace/cse522s/studio4/subdir3 $ mount --bind ../subdir0/myfile myfile
mount: only root can use "--bind" option
pi@xingjian:~/Documents/userspace/cse522s/studio4/subdir3 $ sudo mount --bind ../subdir0/myfile myfile
pi@xingjian:~/Documents/userspace/cse522s/studio4/subdir3 $ cd ..
pi@xingjian:~/Documents/userspace/cse522s/studio4 $ sudo mount --bind subdir0 subdir4
Again, using ls -i * under studio4, we should see identical inode numbers:
pi@xingjian:~/Documents/userspace/cse522s/studio4 $ ls -i *
subdir0:
390048 myfile
subdir1:
390048 myfile
subdir2:
390048 myfile
subdir3:
390048 myfile
subdir4:
390048 myfile
Accessing the Virtual Filesystem
To support various native filesystem and, at the same time, to allow access to files of other operating systems, the Linux kernel includes a layer between user processes (or the standard library) and the filesystem implementation. This layer is known as the Virtual Filesystem, or VFS for short.
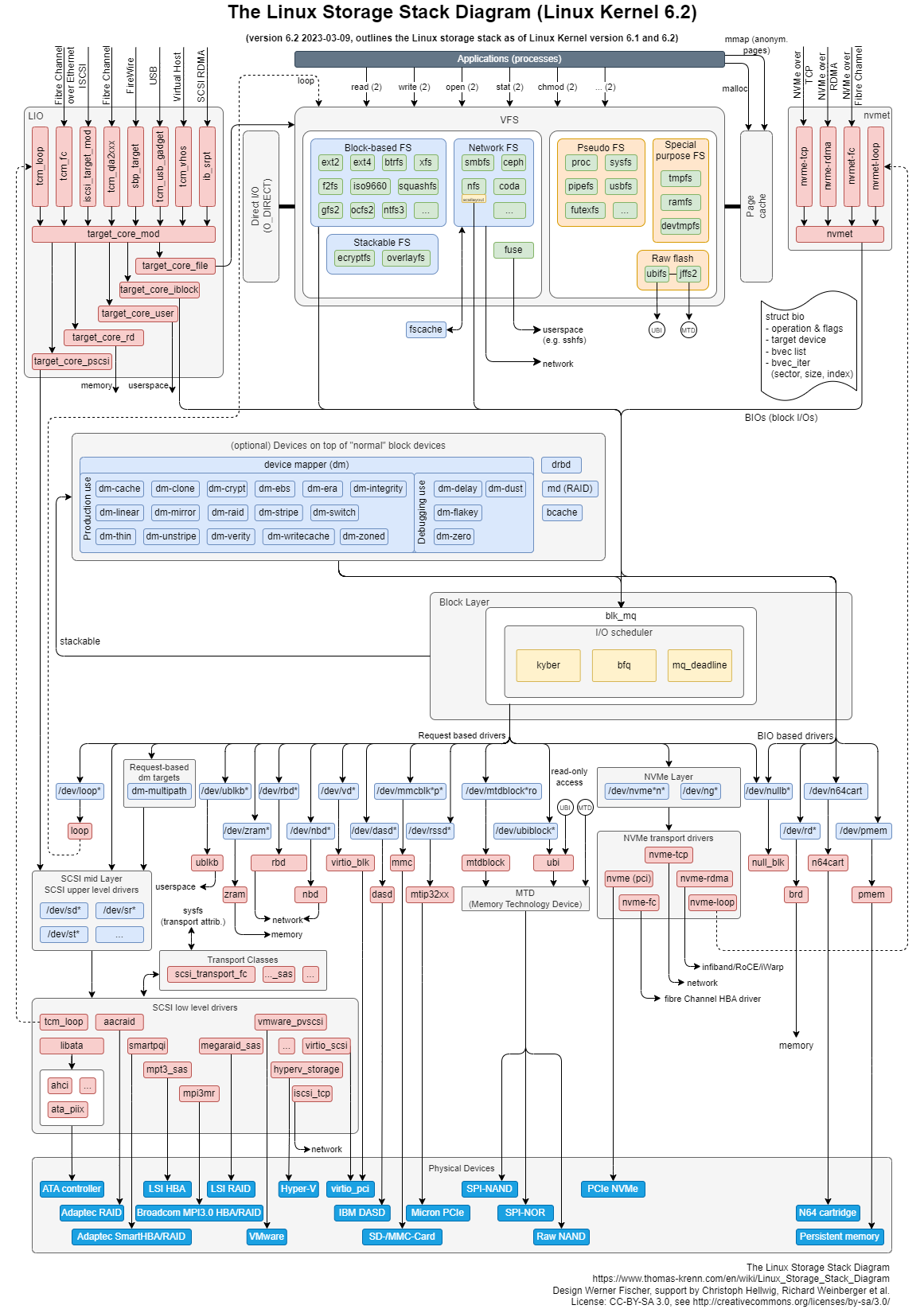
The VFS has the following important data structures:
- File: This represents the open file and captures the information, like offset, and so on. The userspace has a handle to an opened file via a structure called the file descriptor. This is the handle used to interface with the filesystem.
- Inode: This is mapped \(1:1\) to the file. The inode is one of the most critical structures and holds the metadata about the file. As an example, it includes in which data blocks the file data is stored and which access permissions are on the file. This information is part of the inode. Inodes are also stored on disk by the specific filesystem, but there is a representation in memory that is part of the VFS layer. The filesystem is responsible for enumerating the VFS inode structure.
- Dentry: This is the mapping between filename and inode. This is an in-memory structure and is not stored on disk. This is mainly relevant to lookup and path traversal.
- Superblock: This structure holds all the information about the filesystem, including how many blocks are there, the device name, and so on. This structure is enumerated and brought into memory during a mount operation.
First, let’s write a kernel module that spawns a single kernel thread. That thread should use the current macro to access its own process descriptor (struct task_struct declared in include/linux/sched.h) and print out the values (i.e., the addresses) of three of its task_struct’s fields to the system log: fs_struct (filesystem structure), files_struct (open file table structure), and nsproxy (namespace proxy structure). The latest Linux version implements fs_struct, files_struct, nsproxy structures as:
// In: include/linux/fs_struct.h
struct fs_struct {
int users;
spinlock_t lock;
seqcount_spinlock_t seq;
int umask;
int in_exec;
struct path root, pwd;
} __randomize_layout;
// In: include/linux/fdtable.h
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
// In: include/linux/nsproxy.h
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
The nsproxy structure holds the eight namespace data structures. We use namespaces to restrict the visibility of resources for processes (by putting the processes in separate namespaces). The missing one is the user namespace, which is part of the cred data structure in the task_struct (i.e., the security context of a task):
// In: include/linux/cred.h
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct ucounts *ucounts;
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;
The kernel module code I used:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
static struct task_struct *task = NULL;
static struct fs_struct *fs;
static struct files_struct *files;
static struct nsproxy *nsproxy;
static int thread_fn(void *data)
{
printk(KERN_INFO "A single kernel thread:\t");
while (1) {
fs = current->fs;
files = current->files;
nsproxy = current->nsproxy;
printk(KERN_INFO "fs at 0x%p, files at 0x%p, nsproxy at 0x%p.\n", fs, files, nsproxy);
set_current_state(TASK_INTERRUPTIBLE);
schedule();
if (kthread_should_stop())
break;
}
return 0;
}
static int hello_init(void)
{
printk(KERN_INFO "Studio 13: VFS Layer\n");
task = kthread_run(thread_fn, NULL, "single thread");
if (IS_ERR(task)) {
printk(KERN_ERR "thread_fn cannot be spawned!\n");
}
return 0;
}
static void hello_exit(void)
{
kthread_stop(task);
printk(KERN_INFO "Out, out, brief candle!\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("x.xingjian");
MODULE_DESCRIPTION("CSE 422S Studio 13");
I obtained the following output:
[ +0.000517] Studio 13: VFS Layer
[ +0.002092] A single kernel thread:
[ +0.000020] fs at 0x5032f332, files at 0x28636248, nsproxy at 0x33adbf95.
[ +5.427644] Out, out, brief candle!
Exploring Directory Entries
Next, modify the module code so that the kernel thread is able to access two fields of the filesystem structure: root and pwd. Specifically, modify the module code so that its kernel thread prints out the values (i.e., the addresses) of both of the path structures’ dentry fields. The code should also check if the pointer values differ; if so, print out the strings in the d_iname fields of the directory entry structures to which they each point; otherwise, if they point to the same directory entry structure, print out the string for its d_iname field.
To start with, I declared four static structures prior to the thread function:
static struct path pwd;
static struct path root;
static struct dentry *pwd_dentry;
static struct dentry *root_dentry;
Inside the thread function, they are initialized as follows:
pwd = fs->pwd;
root = fs->root;
pwd_dentry = pwd.dentry;
root_dentry = root.dentry;
Two more headers are included for successful compilation: <linux/fs_struct> and <linux/dcache.h>. The dcache caches information about names in each filesystem to make them quickly available for lookup. The dentry structures are implemented as a RCU-protected hash list in the Linux kernel, which can be found in include/linux/dcache.h. The d_iname field has the following declaration:
unsigned char d_iname[DNAME_INLINE_LEN];
in which the string length is \(64\) byte-aligned. Load and then unload this new kernel module on the Raspberry Pi. The results are presented below:
[ +0.001389] Studio 13: VFS Layer
[ +0.000313] A single kernel thread:
[ +0.000019] fs at 0x1833eb79, files at 0xee7622f1, nsproxy at 0x1d7dad2e.
[ +0.000015] pwd_dentry: 0x4d5fb381
[ +0.000012] root_dentry: 0x4d5fb381
[ +0.000009] d_iname of pwd_dentry: /
[ +0.000009] Same dentry pointers!
[Jan25 15:50] Out, out, brief candle!
We can see that both two dentry pointers point to the root directory. This is because the module is compiled with root privilege.
Now, let’s modify the module code so that it prints the names of all of the files and directories that are within the root directory. To do so, its kernel thread will have to traverse the list of directory entries whose head is in the d_subdirs field of the directory entry structure to which the path structure for the root directory points. Because d_subdirs points to a child entry, once we have reached the first child directory entry, we will then have to traverse the list of its siblings. The head of this list is d_child fields of the directory entry structure.
Inside the dentry structure, there are two fields:
struct list_head d_child; /* For directories, pointers for the list of directory dentries in the same parent directory */
struct list_head d_subdirs; /* For directories, head of the list of subdirectory dentries */
d_subdirs points to a child entry and d_child is the member list head. The list_for_each_entry macro, which iterates over a list of given type, is defined in include/linux/list.h as follows:
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
in which pos is the type pointer to use as a loop cursor, head is the list head, member is the name of the list_head within the list. Starting from this generic setup, we can iterate over each child entry using the following code:
rcu_read_lock();
list_for_each_entry( child_dentry, &(root_dentry->d_subdirs), d_child ) {
printk(KERN_INFO "%s\n", child_dentry->d_iname);
}
rcu_read_unlock();
The output kernel log has \(10\) lines that are not displayed by ls -l /: .flatpak-info, lib64, efi, forcequotacheck, .local, .config, none, forcefsck, fastboot, selinux. To account for this phenomenon, we should recall from the LKD book that:
The
dentryobject does not correspond to any sort of on-disk data structure. The VFS creates it on-the-fly from a string representation of a path name. Because thedentryobject is not physically stored on the disk, no flag instruct dentryspecifies whether the object is modified (that is, whether it is dirty and needs to be written back to disk).A valid
dentryobject can be in one of three states:used,unused, ornegative. A useddentrycorresponds to a validinode(d_inodepoints to an associatedinode) and indicates that there are one or more users of the object (d_countis positive). A useddentryis in use by the VFS and points to valid data and, thus, cannot be discarded. An unuseddentrycorresponds to a validinode(d_inodepoints to aninode), but the VFS is not currently using thedentryobject (d_countis zero). Because thedentryobject still points to a valid object, thedentryis kept around — cached — in case it is needed again. Because thedentryhas not been destroyed prematurely, thedentryneed not be recreated if it is needed in the future, and path name lookups can complete quicker than if thedentrywas not cached. If it is necessary to reclaim memory, however, thedentrycan be discarded because it is not in active use. A negative, or invalid,dentryis not associated with a validinode(d_inodeisNULL) because either theinodewas deleted or the path name was never correct to begin with. Thedentryis kept around, however, so that future lookups are resolved quickly.
If a user types “more cowbell” and no file named “cowbell” exists, the kernel will create a negative dentry recording that fact. Negative dentrys can improve system performance by failing repeated accesses to a given non-existent file without having to invoke the underlying filesystem. Based on the above information, the code can be modified into:
rcu_read_lock();
list_for_each_entry( child_dentry, &(root_dentry->d_subdirs), d_child ) {
if (child_dentry->d_inode != NULL) {
printk(KERN_INFO "%s\n", child_dentry->d_iname);
}
}
rcu_read_unlock();
Then the system log messages output the same dentry names as the ls -l / command.
This time, let’s modify the kernel module code so that, as its kernel thread traverses the list of directory entries in the d_subdirs field of the root directory entry, it only prints the value of an entry’s d_iname field if that entry’s d_subdirs list is non-empty.
If I use the following code snippet:
rcu_read_lock();
list_for_each_entry( child_dentry, &(root_dentry->d_subdirs), d_child ) {
if ( !list_empty(&(child_dentry->d_subdirs)) ) {
printk(KERN_INFO "%s\n", child_dentry->d_iname);
}
}
rcu_read_unlock();
Seven directory names are printed out:
[ +0.000010] opt
[ +0.000010] root
[ +0.000009] tmp
[ +0.000011] home
[ +0.000010] var
[ +0.000010] etc
[ +0.000009] usr
If I compile with the following code snippet:
rcu_read_lock();
list_for_each_entry( child_dentry, &(root_dentry->d_subdirs), d_child ) {
printk(KERN_INFO "%s\n", child_dentry->d_iname);
if ( !list_empty(&(child_dentry->d_subdirs)) ) {
list_for_each_entry( child_sub_dentry, &(child_dentry->d_subdirs), d_child ) {
printk(KERN_INFO "\\%s\n", child_sub_dentry->d_iname);
}
}
}
rcu_read_unlock();
Open the /var/log/syslog file, I can see a long list of name strings. The last \(17\) lines are:
[ +0.000014] usr
[ +0.000011] \libexec
[ +0.000013] \src
[ +0.000011] \tmp
[ +0.000011] \pyvenv.cfg
[ +0.000011] \games
[ +0.000013] \include
[ +0.000014] \arm-linux-gnueabihf
[ +0.000011] \man
[ +0.000011] \etc
[ +0.000011] \pkg
[ +0.000012] \X11R6
[ +0.000011] \share
[ +0.000011] \sbin
[ +0.000011] \local
[ +0.000024] \bin
[ +0.000018] \lib
In comparison to using the command ls -l /, the contents of the root directory is displayed within \(19\) lines.
Exploring File-Related Structures
A file descriptor is an unsigned integer used by a process to identify an open file. File descriptors are indices to the file descriptor table in the userspace and the file descriptor table takes kernel memory for each process because it is stored in the kernel’s data structure for the process image.
// In: include/linux/fdtable.h
static inline struct file *fcheck_files(struct files_struct *files, unsigned int fd)
{
RCU_LOCKDEP_WARN(!rcu_read_lock_held() && !lockdep_is_held(&files->file_lock), "suspicious rcu_dereference_check() usage");
return __fcheck_files(file, fd);
}
static inline struct file *__fcheck_files(struct files_struct *files, unsigned int fd)
{
struct fdtable *fdt = rcu_dereference_raw(files->fdt);
if (fd < fdt->max_fds) {
fd = array_index_nospec(fd, fdt->max_fds);
return rcu_dereference_raw(fdt->fd[fd]);
}
return NULL;
}
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd;
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};
According to the Linux kernel documentation:
Up until 2.6.12, the file descriptor table has been protected with a lock and reference count . . . In the new lock-free model of file descriptor management, the reference counting is similar, but the locking is based on RCU . . . In order for the updates to appear atomic to a lock-free reader, all the elements of the file descriptor table are in a separate structure —
struct fdtable.files_structcontains a pointer tostruct fdtablethrough which the actual file descriptor table is accessed.
To look up the file structure given an fd, a reader must use either fcheck() or fcheck_files() APIs. Following the approach taken by Eric W. Biederman (see this patch), I added rcu_read_lock and rcu_read_unlock functions around fcheck_files(). struct file_operations *f_op is the structure of operations associated with the file. The kernel assigns the pointer as part of its implementation of open and then reads it when it needs to dispatch any operations. The value in filp->f_op (filp is the pointer to struct file) is never saved by the kernel for later reference; this means that we can change the file operations associated with our file, and the new methods will be effective after we return to the caller.
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/fdtable.h>
#include <linux/fs.h>
#include <linux/fs_struct.h>
#include <linux/dcache.h>
static struct task_struct *task = NULL;
static struct fs_struct *fs;
static struct files_struct *files;
static struct nsproxy *nsproxy;
static struct path pwd;
static struct path root;
static struct dentry *pwd_dentry;
static struct dentry *root_dentry;
static const char *msg = "Hello from VFS Studio";
static pid_t pid = 666;
module_param(pid, int, 0); // The pid_t data type is a signed integer type
static int thread_fn(void *data)
{
size_t msg_len;
struct pid *pid_ptr;
struct task_struct *task_ptr;
struct files_struct *files_ptr;
struct file *file_ptr;
// const struct file_operations *fops_ptr;
loff_t offset;
ssize_t ret;
printk(KERN_INFO "A single kernel thread:\n");
msg_len = strlen(msg) + 1;
pid_ptr = find_get_pid(pid);
if (IS_ERR(pid_ptr)) {
printk(KERN_DEBUG "Error here: %ld\n", PTR_ERR(pid_ptr));
return -1;
}
task_ptr = get_pid_task(pid_ptr, PIDTYPE_PID);
if (IS_ERR(task_ptr)) {
printk(KERN_DEBUG "Error here: %ld", PTR_ERR(task_ptr));
return -1;
}
files_ptr = task_ptr->files;
rcu_read_lock();
file_ptr = fcheck_files(files_ptr, 1); // Standard output has file descriptor 1
if (IS_ERR(file_ptr))
printk(KERN_DEBUG "Error here: %ld", PTR_ERR(file_ptr));
rcu_read_unlock();
// fops_ptr = file_ptr->f_op;
offset = 0;
ret = file_ptr->f_op->write(file_ptr, msg, msg_len, &offset);
if (ret >= 0) printk(KERN_DEBUG "Write successful!\n");
while (1) {
fs = current->fs;
files = current->files;
nsproxy = current->nsproxy;
printk(KERN_INFO "fs at 0x%p, files at 0x%p, nsproxy at 0x%p.\n", fs, files, nsproxy);
pwd = fs->pwd;
root = fs->root;
pwd_dentry = pwd.dentry;
root_dentry = root.dentry;
printk(KERN_INFO "pwd_dentry: 0x%p\n", pwd_dentry);
printk(KERN_INFO "root_dentry: 0x%p\n", root_dentry);
printk(KERN_INFO "d_iname of pwd_dentry: %s\n", pwd_dentry->d_iname);
if (pwd_dentry != root_dentry) {
printk(KERN_INFO "d_iname pf root_dentry: %s\n", root_dentry->d_iname);
printk(KERN_INFO "Two dentry pointers differ!\n");
}
printk(KERN_INFO "Same dentry pointers!\n");
set_current_state(TASK_INTERRUPTIBLE);
schedule();
if (kthread_should_stop()) break;
}
return 0;
}
static int hello_init(void)
{
printk(KERN_INFO "Studio 13: VFS Layer\n");
task = kthread_run(thread_fn, NULL, "single thread");
if (IS_ERR(task)) {
printk(KERN_ERR "thread_fn cannot be spawned!\n");
}
return 0;
}
static void hello_exit(void)
{
kthread_stop(task);
printk(KERN_INFO "Out, out, brief candle!\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("x.xingjian");
MODULE_DESCRIPTION("CSE 422S Studio 13");
Footnotes
-
Jonathan Corbet, Linux Device Drivers, Third Edition, https://lwn.net/Kernel/LDD3/. ⤴
-
Before we can access the files on a filesystem, we need to mount the filesystem. When we mount a filesystem, we attach that filesystem to a directory (mount point) and make it available to the system. The root (
/) filesystem is always mounted. ⤴ -
If you are familiar with containers, you might know that containers work on the concept of bind mounts. (For those not familiar with containers, a container is a self-contained environment that shares the kernel of the host system.) When a volume is created for a container, it is actually a bind mount of a directory within the host to a mount point within the container’s filesystem. Since the mount happens within the mount namespace, the
vfsmountstructures are scoped to the mount namespace. This means that, by creating a bind mount of a directory, we can expose a volume within the namespace that is holding the container. ⤴
Last updated: 2023-02-11